


Picture this: You’re sipping your morning coffee when notifications start flooding your phone. Your application dashboards turn red. Customer support tickets surge. Revenue streams halt. Welcome to the reality of a major AWS outage—a scenario that transforms from theoretical risk to business-critical emergency in minutes.
The October 2025 AWS outage wasn’t an isolated incident. It was the latest reminder that even the world’s most sophisticated cloud infrastructure remains vulnerable to cascading failures that can paralyze entire industries within minutes.
With direct financial losses estimated between $500 million and $650 million to US companies alone, the question facing every technology leader isn’t if another major outage will occur—it’s when, and whether your infrastructure can survive it.
The October 2025 AWS Outage: A Timeline of Cascade Failure
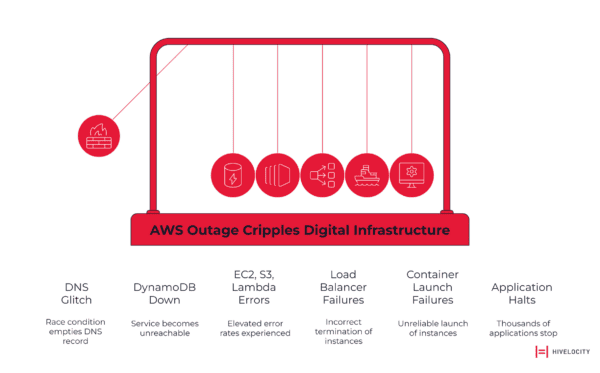
On October 20, 2025, at approximately 2:48 AM Eastern Time, a significant portion of the internet went dark. What began as a seemingly minor DNS glitch would spiral into a 15-hour disruption that exposed the fragility of our interconnected digital infrastructure.
The technical root cause traced back to what AWS described as a “latent defect” in their automated DNS management system—a race condition where two programs attempted to write to the same DNS entry simultaneously, resulting in an empty record. This small error had catastrophic consequences: all IP addresses for the DynamoDB regional endpoint were accidentally deleted, rendering the service unreachable.
But the real damage came from the cascade effect. Once DynamoDB became unavailable, a domino effect rippled through the ecosystem:
- EC2, S3, and Lambda experienced elevated error rates as they relied on DynamoDB for core operations
- Network Load Balancers began incorrectly terminating healthy instances due to communication delays
- Container orchestration services like ECS and EKS failed to launch new instances reliably
- Dependent applications across thousands of organizations ground to a halt
High-profile platforms felt the impact immediately. Slack went offline. Snapchat stopped working. Reddit became inaccessible. Financial applications including Venmo and Robinhood reported disruptions. Even Amazon’s own services—its retail website, Prime Video, and Alexa—experienced significant problems.
The outage generated 11 million outage reports and affected an estimated 70,000 organizations, including over 2,000 large enterprises. Full recovery wasn’t declared until 6:00 PM EDT—nearly 15 hours after the initial failure.
Why US-EAST-1 Keeps Breaking the Internet
If you’ve been tracking AWS outages, you’ve noticed a pattern: the US-EAST-1 region in Northern Virginia keeps appearing as the epicenter of major disruptions. This isn’t coincidence—it’s concentration risk at a massive scale.
As AWS’s oldest and largest cloud hub, US-EAST-1 hosts a disproportionate share of critical workloads. Many organizations default to this region for legacy reasons, latency considerations, or simply because it was their first choice years ago. This creates what experts call a “massive concentration risk” where a single regional failure doesn’t just affect individual applications—it disrupts foundational services that power much of the internet’s infrastructure.
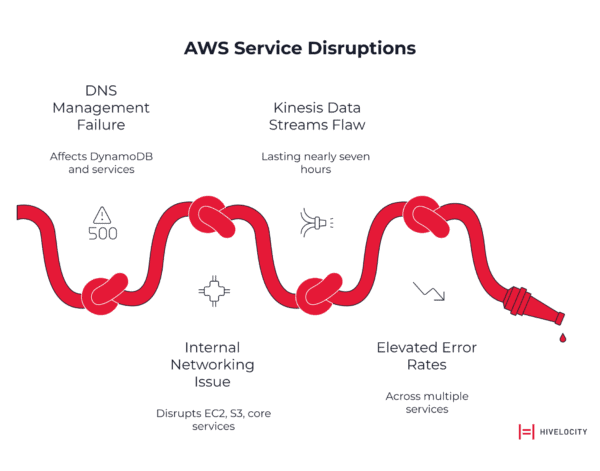
Consider the historical pattern:
- October 2025: DNS management failure affecting DynamoDB and dependent services
- February 2025: Internal networking issue in eu-north-1 (Stockholm) disrupting EC2, S3, and other core services
- July 2024: Kinesis Data Streams flaw in US-EAST-1 lasting nearly seven hours
- June 2023: Elevated error rates across multiple services in US-EAST-1
The lesson is clear: geographic diversity matters. A multi-cloud strategy provides little protection if all your workloads run in data centers susceptible to the same regional risks. Building resilient infrastructure requires mapping critical business functions to specific cloud regions and understanding that not all regions carry equal systemic risk.
The Real Cost of AWS Downtime (And Why SLAs Don’t Cover It)
Let’s talk numbers. The October 2025 outage cost businesses an estimated $500-$650 million in direct financial losses. Industry data shows the median cost of a high-impact IT outage reaches approximately $1.9 million per hour. These aren’t abstract figures—they represent real revenue losses, productivity costs, and recovery expenses that compound with every passing minute.
Now consider AWS’s Service Level Agreement. The Compute SLA promises 99.99% monthly uptime for multi-Availability Zone deployments—less than five minutes of permissible downtime per month. When breaches occur, the remedies are modest:
- 10% service credit if uptime falls between 99.0% and 99.99%
- 30% service credit if uptime drops between 95.0% and 99.0%
- 100% service credit if uptime falls below 95.0%
Here’s the uncomfortable truth: a 10% credit on your monthly AWS bill doesn’t come close to covering hundreds of thousands or millions in lost revenue. These credits represent a fraction of actual financial losses and only apply to future bills—not refunds. They require documentation and claims filed within two billing cycles, adding administrative overhead during crisis periods when teams are focused on recovery.
SLAs are liability-limiting instruments for vendors, not financial protection for customers. The vast majority of downtime risk remains with your organization. This is the harsh reality of the Shared Responsibility Model—AWS provides infrastructure, but you’re responsible for designing resilient applications that can withstand infrastructure failures.
How AWS Outages Actually Happen: Understanding Service Dependencies
To build resilient systems, you need to understand how failures propagate through AWS’s interconnected architecture. The October 2025 incident provides a textbook example.
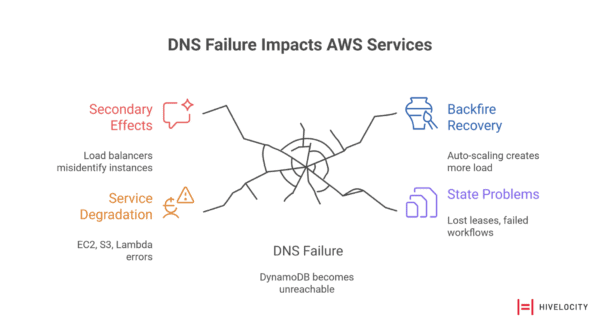
The initial DNS failure affected DynamoDB, but the consequences extended far beyond a single database service. Modern cloud architectures are built on layers of dependencies where services rely on other services to function. When a foundational service like DynamoDB fails, it triggers a cascade:
- Primary service fails (DynamoDB becomes unreachable due to DNS issues)
- Dependent services degrade (EC2, S3, Lambda experience elevated errors)
- Secondary effects multiply (Load balancers misidentify healthy instances as failed)
- Recovery mechanisms backfire (Auto-scaling and health checks create additional load)
- System accumulates state problems (lost leases, failed workflows, stale caches)
This explains why AWS status pages turning green doesn’t mean your applications are instantly recovered. The system has accumulated a massive backlog of state problems that require meticulous, time-consuming effort to resolve. Engineers on the frontlines understand that restoring the foundational service is just the beginning of a long recovery process.
Comprehensive observability requires visibility beyond traditional metrics. You need to monitor:
- DNS health and resolution times for critical service endpoints
- Inter-service connectivity including network latency and error rates
- Service discovery mechanisms ensuring reliable communication between components
- Cloud provider dependencies with real-time mapping of service interdependencies
Traditional monitoring focused on CPU and memory metrics is insufficient. The October 2025 outage brought down the entire system through a failure in a “hidden layer”—DNS—even while individual servers appeared healthy on dashboards.
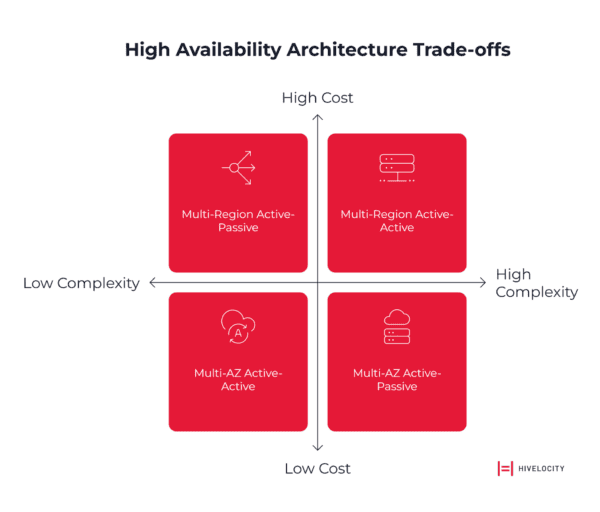
Strategic Approaches to High Availability Architecture
Building resilient systems requires moving beyond single-region deployments to architectures that can withstand cascade failures. Your primary options are Multi-Availability Zone (Multi-AZ) and Multi-Region architectures, each with distinct trade-offs.
Multi-Availability Zone Architecture
Multi-AZ represents the baseline for high availability. It distributes resources across physically distinct data centers within a single AWS region. This approach:
- Protects against localized failures like power outages or network issues affecting individual data centers
- Enables low-latency synchronous replication due to geographic proximity
- Offers the most cost-effective redundancy strategy with minimal complexity overhead
Multi-Region Architecture
Multi-region deployments provide protection against systemic regional failures by replicating infrastructure across geographically separate AWS regions. This pattern:
- Guards against large-scale events that could impact entire regions
- Requires asynchronous data replication due to physical distance and latency constraints
- Introduces significant complexity in networking, data consistency, and failover logic
- Carries higher operational costs but provides the strongest disaster recovery capabilities
Active-Active vs. Active-Passive Considerations
Active-Active architectures maintain fully operational infrastructure in multiple locations, enabling immediate failover with minimal service disruption. They require complex data synchronization mechanisms, higher operational costs, and sophisticated traffic routing.
Active-Passive configurations maintain standby infrastructure that activates during primary system failures. This approach offers lower operational costs during normal operations, simpler data replication requirements, and acceptable recovery times for many business scenarios.
The choice between these patterns depends on careful trade-offs between cost, complexity, and your specific Recovery Time Objectives (RTO) and Recovery Point Objectives (RPO).
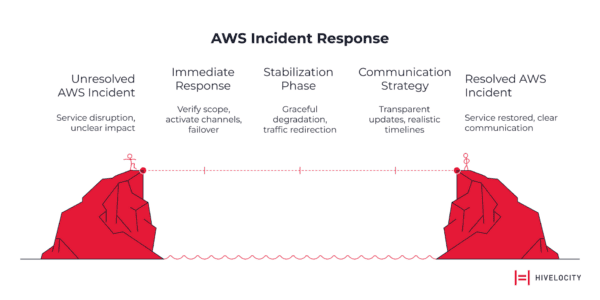
Your Incident Response Playbook: The First 120 Minutes
When AWS infrastructure fails, systematic response guided by pre-defined runbooks becomes critical. Here’s your step-by-step framework:
Immediate Response (0-30 minutes)
- Verify the scope using AWS Health Dashboard and third-party monitoring services
- Activate communication channels to coordinate team response
- Execute predetermined failover procedures based on affected services
Stabilization Phase (30-120 minutes)
- Implement graceful degradation by disabling non-essential features
- Redirect traffic to healthy regions or backup systems
- Monitor recovery progress and adjust strategies based on real-time data
Communication Strategy
Transparent communication during an outage is crucial. Deploy status pages with regular updates. Acknowledge the impact honestly and provide realistic recovery timelines. Maintain customer confidence through timely communication rather than radio silence.
The first time your organization experiences a real-world failure should not be the first time your recovery plan is executed. Quarterly “game days” that simulate large-scale failures test both technical recovery mechanisms and human response procedures, measuring Mean Time to Detect (MTTD) and Mean Time to Recover (MTTR) while refining your runbooks.
The Multi-Cloud Reality: Beyond Vendor Diversification
While multi-cloud strategies offer theoretical protection against single-vendor failures, practical implementation requires careful consideration of trade-offs.
Benefits of Multi-Cloud Architecture
- Reduced concentration risk across cloud providers
- Competitive pricing leverage through vendor competition
- Access to specialized services from different providers
Implementation Challenges
- Increased operational complexity managing multiple platforms
- Higher costs due to data egress fees and duplicated overhead
- Skill set requirements spanning multiple cloud ecosystems
The most pragmatic approach involves containerization and Infrastructure-as-Code tools like Terraform and Kubernetes, which promote application portability across cloud environments without deep vendor lock-in. Start by identifying mission-critical services and building failover capabilities for them first, rather than attempting to migrate your entire application portfolio at once.
Advanced Resilience: Chaos Engineering and Proactive Testing
Having a redundant architecture is meaningless if failover mechanisms are untested. Proactive testing is essential for building confidence and uncovering hidden weaknesses before they manifest during real incidents.
Chaos engineering involves intentionally injecting controlled failures into production or production-like environments to observe how systems respond. Simple experiments include simulating database timeouts, blocking network access to critical dependencies, or injecting latency between microservices.
Game days are scheduled exercises where teams simulate large-scale failure events, such as a full regional outage. These test not only technology but also the human element of incident response: the clarity of runbooks, the effectiveness of communication plans, and the team’s ability to make critical decisions under pressure.
Regular testing reveals gaps in documentation, identifies single points of failure, validates recovery time objectives, and builds muscle memory for incident response teams.
Quantifying Your Resilience Investment
FinOps leaders must balance resilience investments against potential downtime costs using this framework:
Total Cost of Downtime = Lost Revenue + Lost Productivity + Recovery Costs + Reputational Impact
For strategic planning:
- Model various outage scenarios with different duration and scope parameters
- Calculate ROI for resilience architectures comparing investment costs against avoided losses
- Establish metrics that reflect balance between cost efficiency and availability requirements
The ROI calculation can be framed as:
ROI = (Avoided Cost of Downtime – Cost of Resilience Strategy) / Cost of Resilience Strategy
This reframes resilience from a pure expense into a strategic investment in risk mitigation. Multi-AZ architectures are more expensive than single-AZ deployments due to redundant infrastructure and inter-AZ data transfer fees. Multi-region or multi-cloud strategies are significantly more costly still. However, when weighed against the $1.9 million per hour median cost of downtime, these investments become justifiable business decisions rather than optional IT projects.
SLA Hygiene: Documenting and Filing Credits
While SLA credits don’t cover the true cost of downtime, proper evidence tagging and claim procedures can help recoup some costs. Maintain:
- Request logs documenting when services became unavailable
- Monitoring data showing the duration and scope of impact
- Claim templates ready to file within two billing cycles
- Authority matrix defining who has approval to file credits on behalf of the organization
Remember that credits are only issued if the amount exceeds one dollar and are applied against future bills, not issued as refunds.
Building Antifragile Infrastructure: Cultural Transformation
The recurring pattern of AWS outages—with major incidents in October 2025, February 2025, July 2024, and June 2023—demonstrates that significant disruptions are operational realities, not rare anomalies. Organizations that thrive despite these challenges share common characteristics:
Embrace Failure as Inevitable
Stop pursuing unrealistic perfection. Design systems that assume components will fail and can gracefully degrade when they do.
Implement Blameless Post-Mortems
Focus on systemic improvement rather than assigning fault. Analyze what failed, why it failed, and how to prevent similar failures in the future.
Foster Cross-Functional Collaboration
Break down traditional silos between development, operations, security, and finance teams. Resilience requires shared accountability and informed trade-offs.
Design for Degraded Operation
Applications should remain functional despite service failures. Serve read-only content from caches. Temporarily disable non-essential features. Display transparent status messages to users. A degraded but functional experience beats a complete crash.
Is Your Organization Ready for the Next AWS Outage?
The October 2025 AWS outage cost businesses hundreds of millions of dollars and countless hours of emergency response. The question facing every CTO and infrastructure leader is straightforward: will your organization be prepared when the next major outage occurs?
Hivelocity Enterprise Cloud offers a strategic solution for mitigating AWS outage risks through infrastructure diversification and robust disaster recovery capabilities. While AWS, Azure, and GCP dominate public cloud discussions, forward-thinking organizations are exploring alternatives that prioritize reliability and performance without the complexity overhead of traditional multi-cloud strategies.
Learn more about Hivelocity Enterprise Cloud and discover how strengthening your infrastructure resilience strategy can reduce exposure to single-vendor concentration risk.
The data and analysis presented here demonstrate that cloud outages are predictable, recurring events with measurable financial impact. Organizations that treat resilience as a strategic priority—rather than an operational afterthought—position themselves for sustained competitive advantage.
