


The landscape for deploying Large Language Models (LLMs) is undergoing a fundamental realignment.
Escalating model complexity and a persistent scarcity of high-performance GPUs have forced a re-evaluation of CPU inference capabilities. While top-tier GPUs remain the standard for high-throughput serving, their cost and supply constraints present significant challenges.
This post provides a technical analysis of three leading open-weight model families—Meta’s Llama 3, Mistral AI’s diverse portfolio, and DeepSeek’s massive Mixture-of-Experts (MoE) architectures—specifically through the lens of CPU-based infrastructure.
We will explore how their architectural differences impact hardware requirements and performance, and how you can leverage cost-effective solutions like Hivelocity’s Ollama servers for your own deployments.
Understanding GPU Requirements for LLMs
Deploying LLMs effectively hinges on powerful hardware, traditionally high-performance GPUs.
These processors are designed for parallel computations, making them ideal for the matrix multiplication operations at the core of transformer architectures. However, the demand for cutting-edge GPUs like NVIDIA’s H100 and A100 far outstrips supply, creating a significant bottleneck for many organizations.
This scarcity has driven up costs and lengthened deployment timelines, forcing developers and businesses to explore alternative hardware solutions.
As a result, CPU-based inference has emerged as a viable and often more economical option, particularly for applications that do not require massive, concurrent request handling.
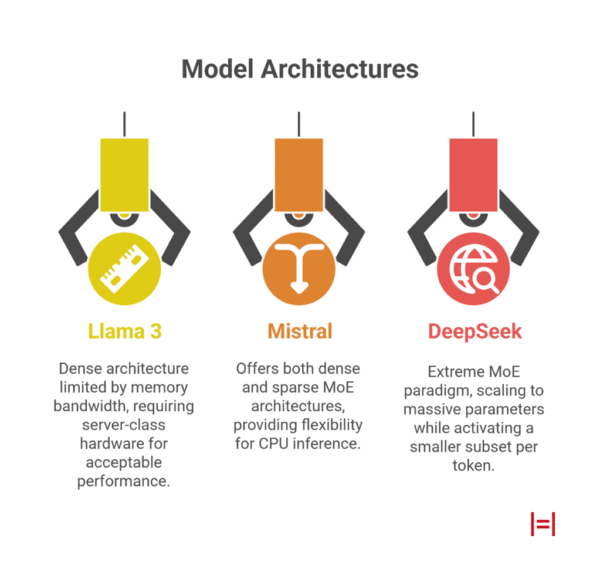
Model Architectures: Dense vs. Sparse
To project hardware requirements for CPU inference, we must first analyze the underlying model architectures. The distinction between dense and sparse models is the most critical factor in determining infrastructure viability, as it dictates how memory bandwidth—the primary bottleneck in CPU inference—is utilized.
Dense Models (Llama 3)
In a dense model, every parameter in the neural network is active for every token generated. This creates a direct, linear relationship between the model’s size and its memory bandwidth consumption.
For example, a forward pass for Llama 3 70B requires loading all 70 billion parameters from system RAM for every single token generated, creating a “memory wall.”
Sparse Models (Mistral, DeepSeek)
Sparse Mixture-of-Experts (MoE) models take a different approach. An MoE architecture involves a router network that selects a specific subset of “experts” (feed-forward network layers) to process each token. This means that while the total number of parameters can be massive, only a fraction are active during inference.
This design can drastically alter the compute-to-memory ratio, but it also introduces the challenge of random memory access, which can lead to latency spikes if not managed efficiently.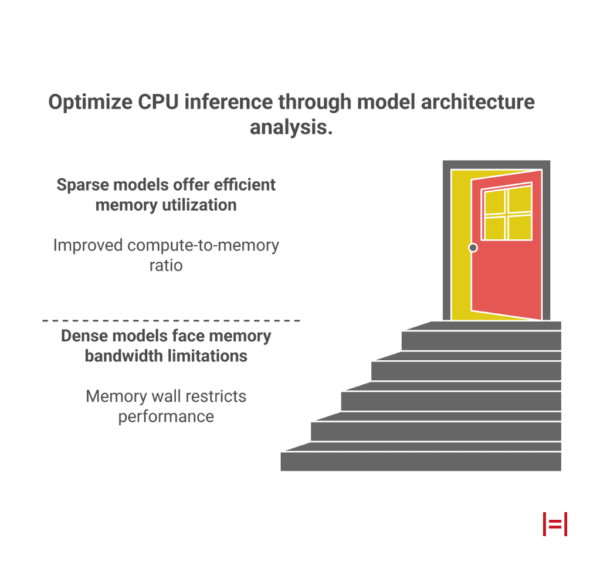
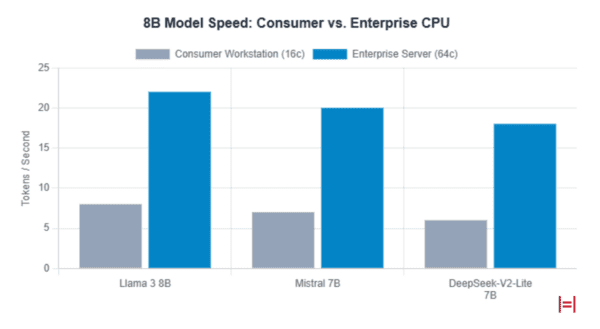
Performance Comparison
The architectural differences between dense and sparse models create distinct performance profiles on non-accelerated hardware.
Llama 3: The Density Bandwidth Challenge
Meta’s Llama 3 family utilizes a dense Transformer architecture, which is fundamentally limited by memory bandwidth. Generating text at a readable speed (e.g., 5-10 tokens per second) with the 70B model requires the system to cycle through the entire model’s weights multiple times per second.
A quantized Llama 3 70B model (around 40GB) demands a theoretical bandwidth of 200-400 GB/s. Consumer dual-channel DDR5 platforms, peaking at 80-90 GB/s, are mathematically incapable of sustaining interactive speeds, often resulting in a sluggish 1.5–2 tokens per second (TPS).
Server-class hardware with 8 or 12-channel memory controllers is needed to achieve acceptable performance.
Mistral: A Hybrid Strategy for Flexibility
Mistral AI offers both optimized dense models and sparse MoE architectures, providing more flexibility for CPU inference.
Their Mixtral 8x22B model uses a sparse architecture where only 39 billion of its 141 billion total parameters are active per token. This reduces the compute requirement but introduces the bottleneck of random memory access.
If the CPU and software are not optimized for this sparse access pattern, cache misses can negate the theoretical bandwidth savings.
On the other hand, a model like Mistral Nemo 12B represents the peak of dense model efficiency, fitting comfortably within the system RAM of modest laptops while outperforming larger legacy models.
DeepSeek: Decoupling Scale and Cost
DeepSeek V3 represents an extreme evolution of the MoE paradigm. It scales to a massive 671 billion parameters, yet only activates 37 billion per token.
This is roughly half the active parameters of a dense Llama 3 70B model, suggesting it could infer twice as fast despite being nearly ten times larger in total storage.
DeepSeek also introduces Multi-Head Latent Attention (MLA), which compresses the KV cache memory usage by up to 93.3%. This is transformative for CPU inference, as it leaves memory channels free to stream model weights even at maximum context lengths.
The primary trade-off is the enormous system RAM required (256GB–512GB) just to hold the model.
CPU Inference Capabilities
The viability of running large models on CPUs has been revolutionized by two key advancements: quantization and optimized software.
Quantization is the process of reducing the precision of model weights (e.g., from 16-bit floating point to 4-bit integers). This is a mandatory requirement for CPU inference, as it dramatically reduces the model’s memory footprint.
The maturation of techniques like importance-matrix-aware methods (I-quants) allows for a granular balance between model performance (perplexity) and resource usage.
Optimized inference engines like Ollama are designed to run LLMs efficiently on CPUs. When paired with a user-friendly interface like OpenWebUI, they make deploying and interacting with models like Llama 3.1 8B straightforward, even without specialized technical expertise.
This is a significant departure from the complex, multi-hour setup traditionally required for self-hosting AI.
For those looking for a cost-effective and private deployment solution, Hivelocity’s pre-configured Ollama servers offer a compelling alternative.
These CPU-based servers come with the Ollama runtime, OpenWebUI, and the Llama 3.1 8B model pre-installed, allowing for deployment in just 5-10 minutes. At 1/5th the cost of GPU hosting and with lower latency than cloud APIs, these servers provide a powerful option for developers and privacy-focused teams.
Your Next Step in AI Deployment
The decision between Llama 3, Mistral, and DeepSeek on CPU infrastructure depends not just on model quality, but on the physical constraints of memory bandwidth and capacity.
While dense models like Llama 3 70B demand high-bandwidth server hardware to be viable, sparse MoE models like DeepSeek V3 open new possibilities for running frontier-class models on CPU servers with sufficient RAM.
For many use cases, smaller, efficient models deployed on cost-effective CPU infrastructure offer the ideal balance of performance, privacy, and control.
The “GPU-only” mentality for LLM inference is becoming obsolete for specific classes of deployment. Intelligent model architecture, combined with hardware-aware software optimizations, can unlock state-of-the-art performance on commodity CPU infrastructure.
If you are ready to explore the power of private, self-hosted AI without the complexity and cost of GPUs, consider a simplified path. Explore Hivelocity’s Ollama servers to deploy a fully configured LLM environment in minutes and take control of your AI journey.
